购买服务器
首先,我们需要买一台显卡云服务器
极度推荐使用雨云,优惠码:wp-admin
账户注册成功后,前往:购买地址
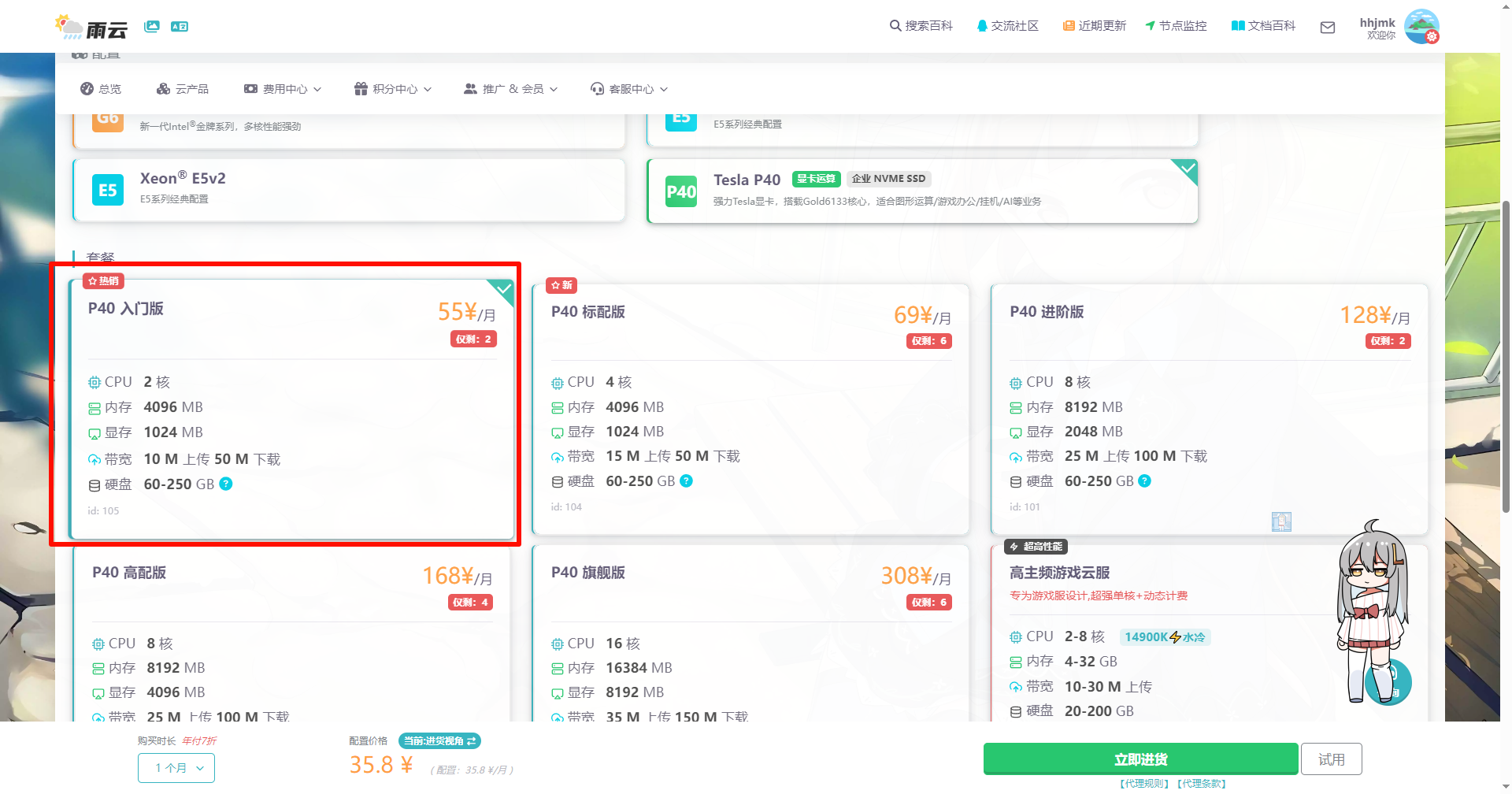
选择宿迁显卡云
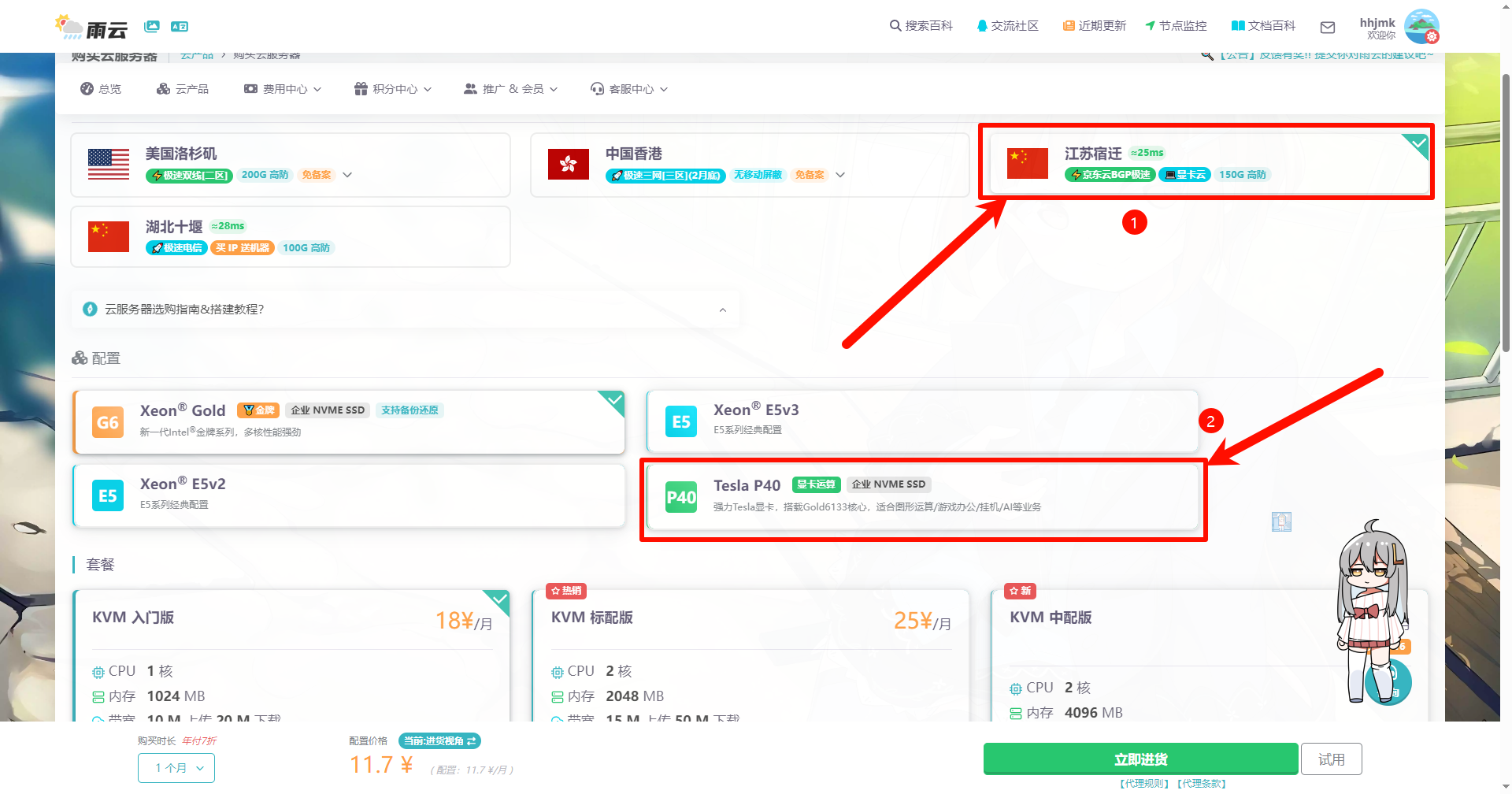
若只是短期使用,建议选择最高配置,如果是长期使用,建议按需选择(主要关注显存)
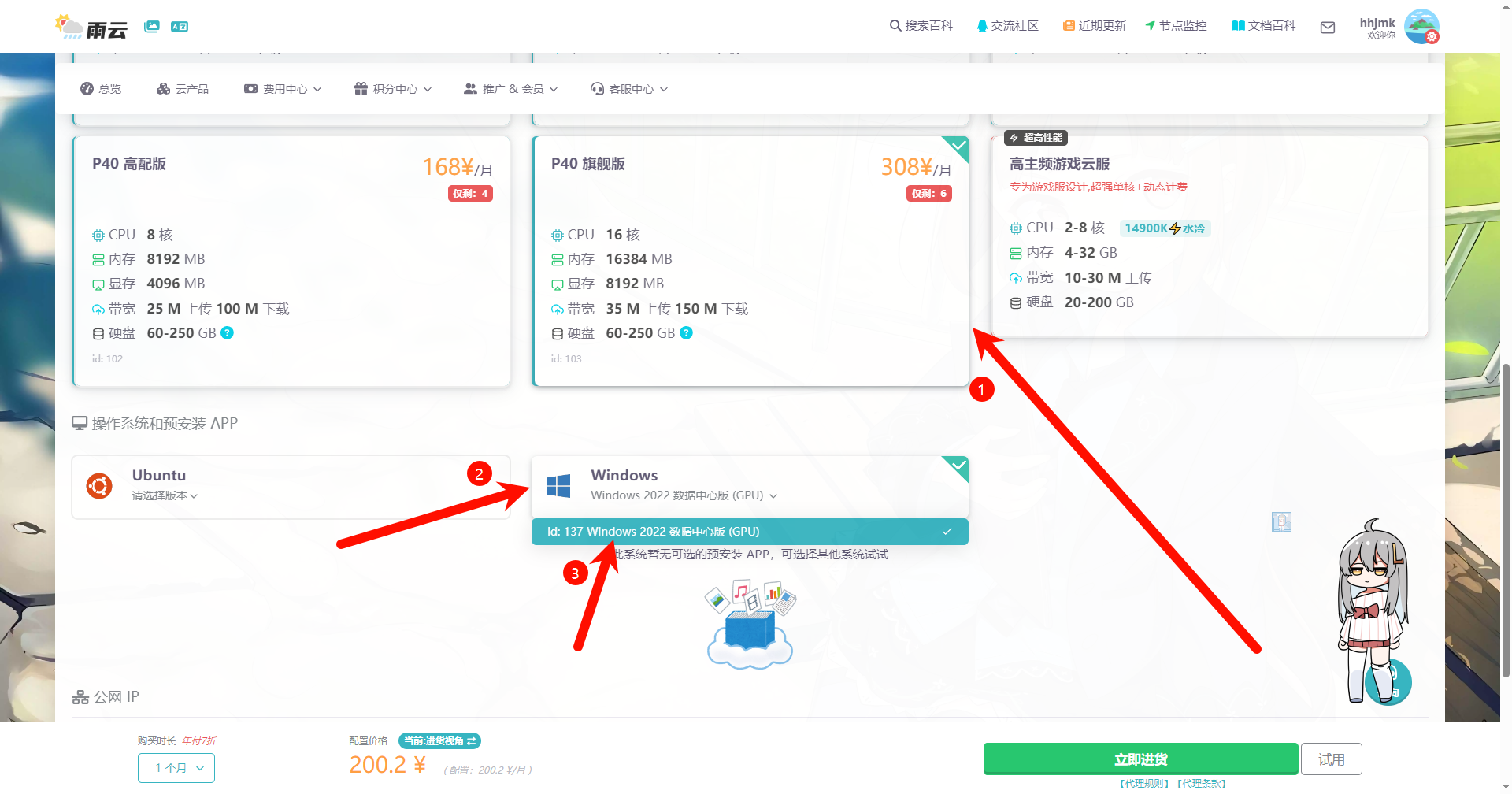
系统选择Windows Server 2022 数据中心版
此系统已默认安装NVIDIA显卡驱动,CUDA已启用,版本如下:
NVIDIA-SMI 537.70, Driver Version: 537.70, CUDA Version: 12.2之后点击右下角的试用即可5元获得一天的使用时长
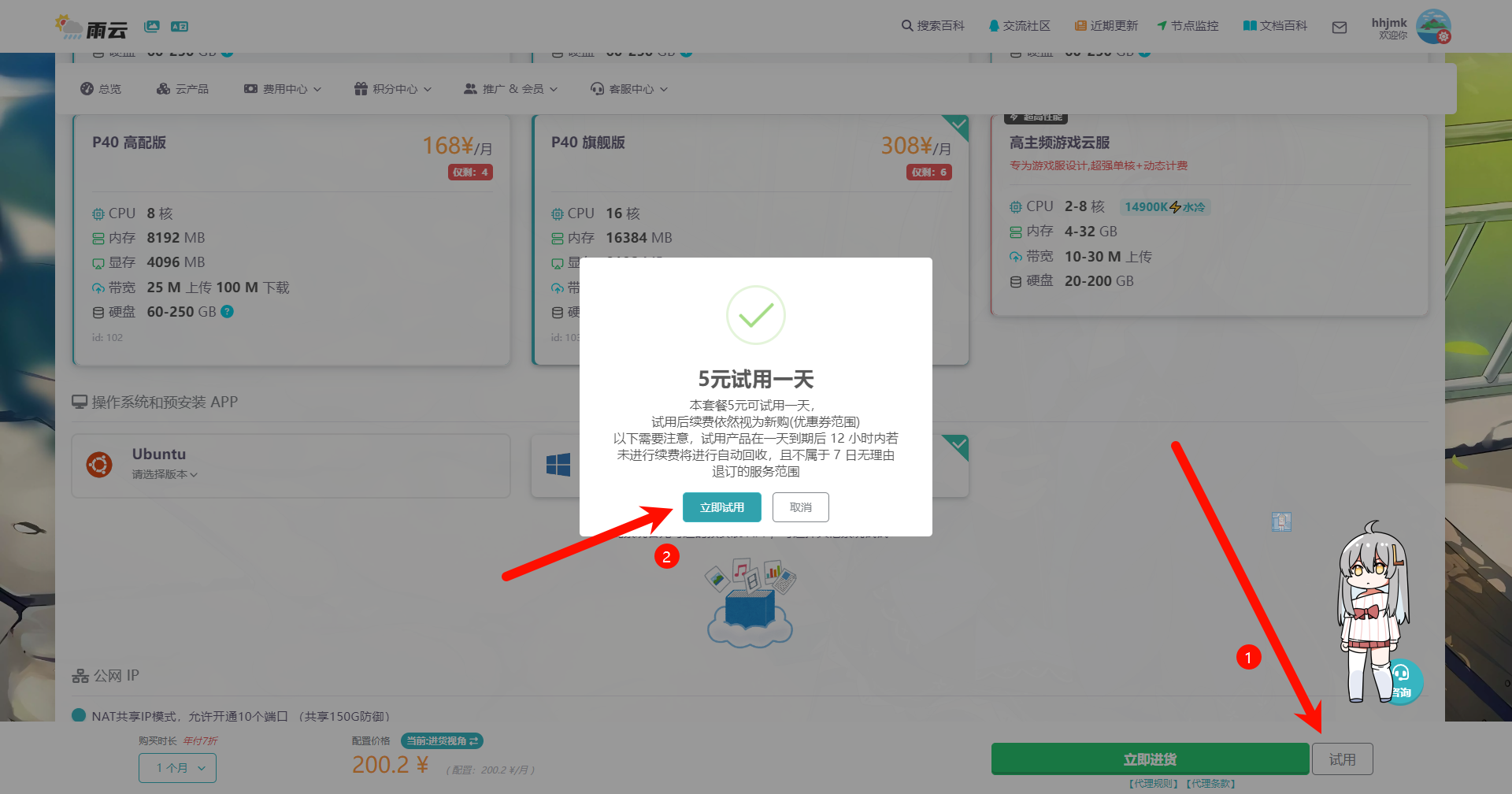
如果GPU资源不足,则可使用更低显存的版本
部署GPT-SoVITS
连接服务器
服务器创建完成后,点击管理进入管理面板
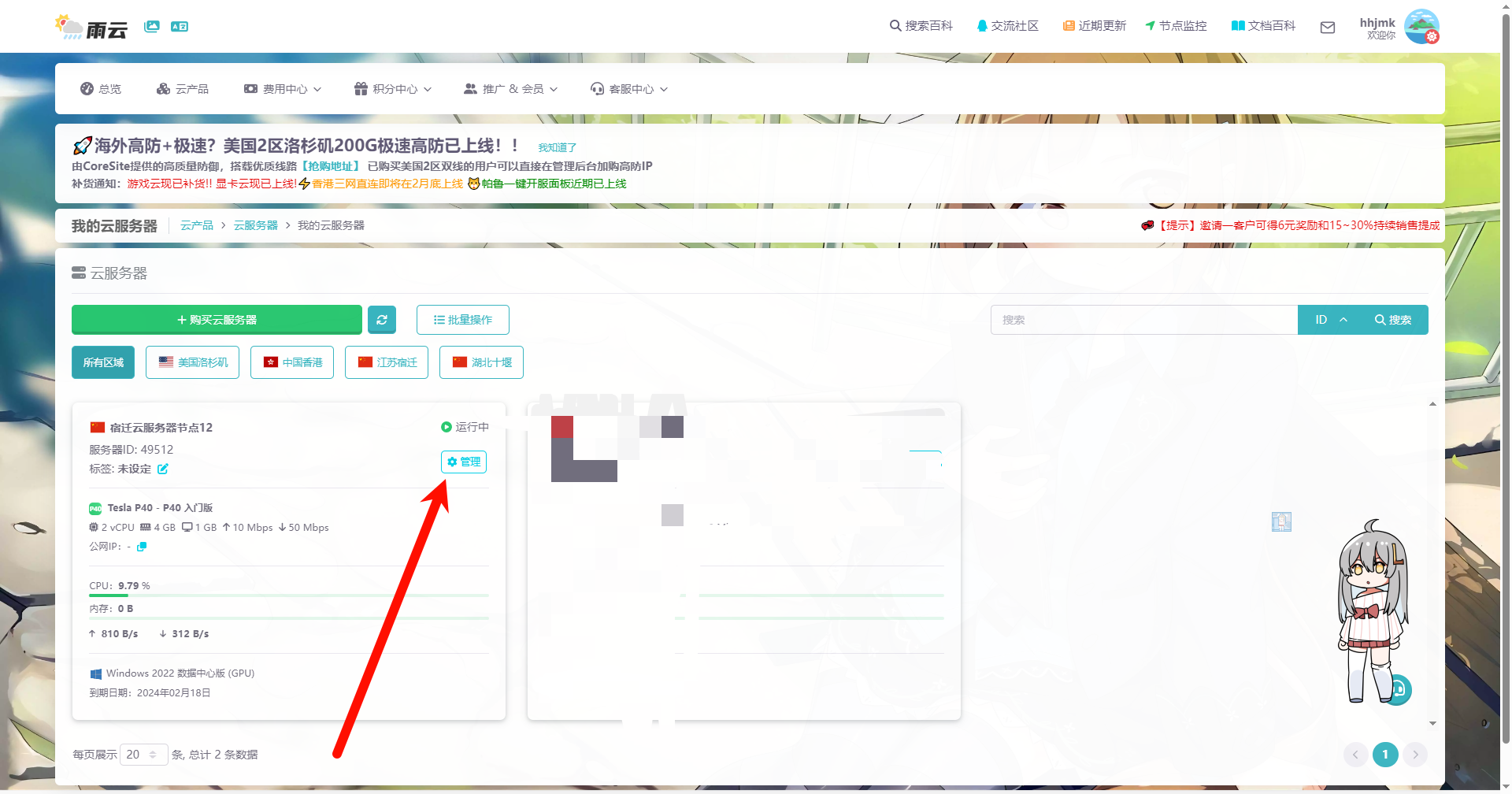
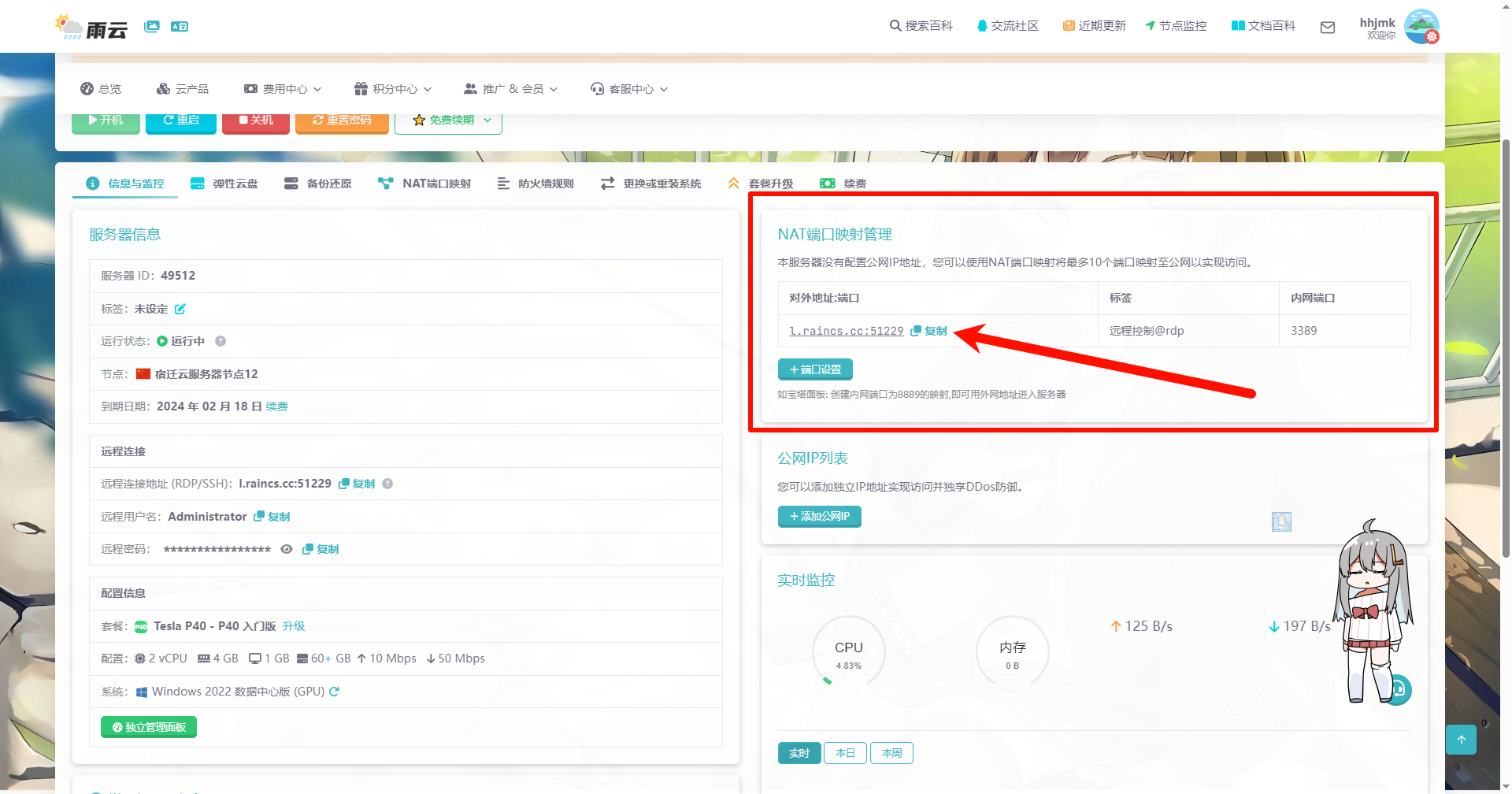
找到首页的NAT端口映射,复制默认生成的地址
之后在你自己的电脑上搜索rdp,找到远程桌面连接并打开
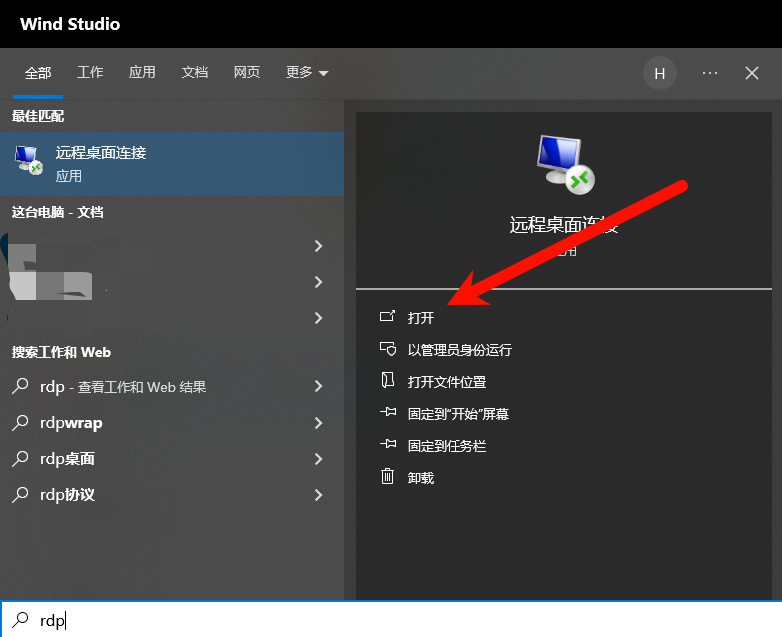
将复制的内容填入“计算机”输入框中,点击“显示选项”
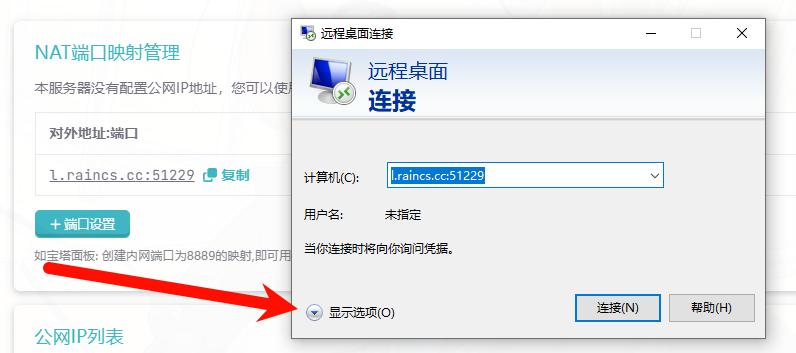
将此处的用户名填入
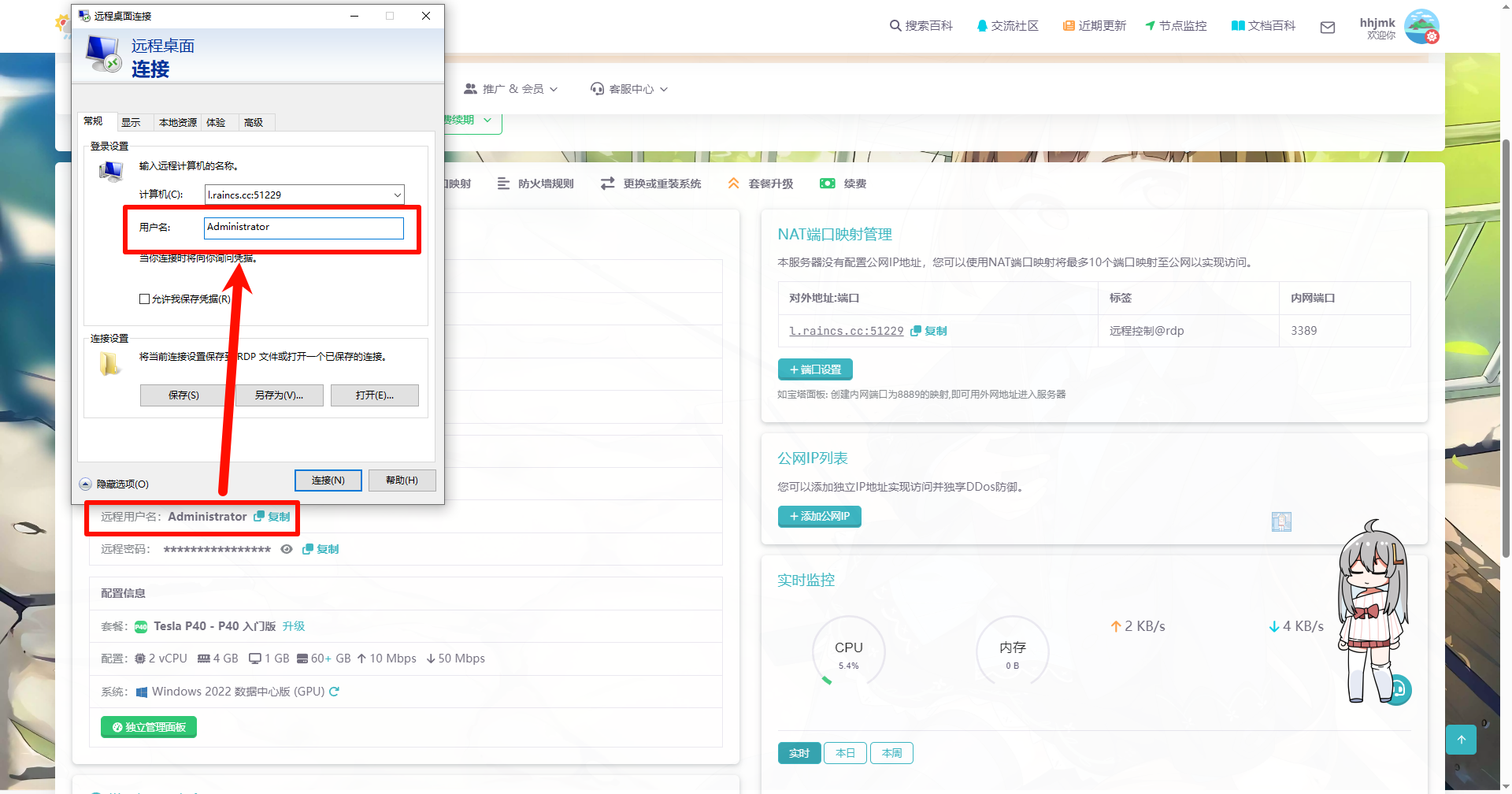
点击连接后会弹出输入密码
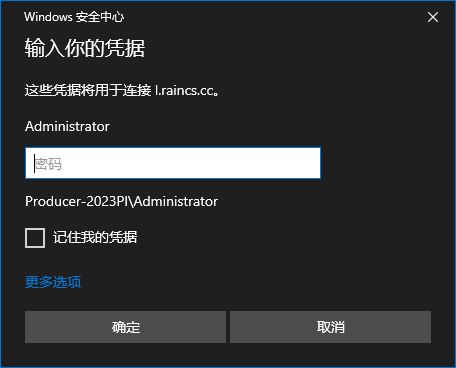
复制并填入“远程密码”

遇到下图提示直接点击是即可
下载
进入桌面后,打开浏览器
之后打开我转存在123Pan的一键包
如果你希望获得最新版的,可以用魔法去抱脸上下载:预打包文件 (huggingface.co)
之后还需要下载纳西妲的语音数据集,这里有大佬打好标的:纳西妲数据集下载
不能用的地址(会报HTTP 414)
之后在服务器上下一个解压软件(请勿使用360、好压等流氓软件),可选的有:
下载时进度卡在100% 0KB/s:
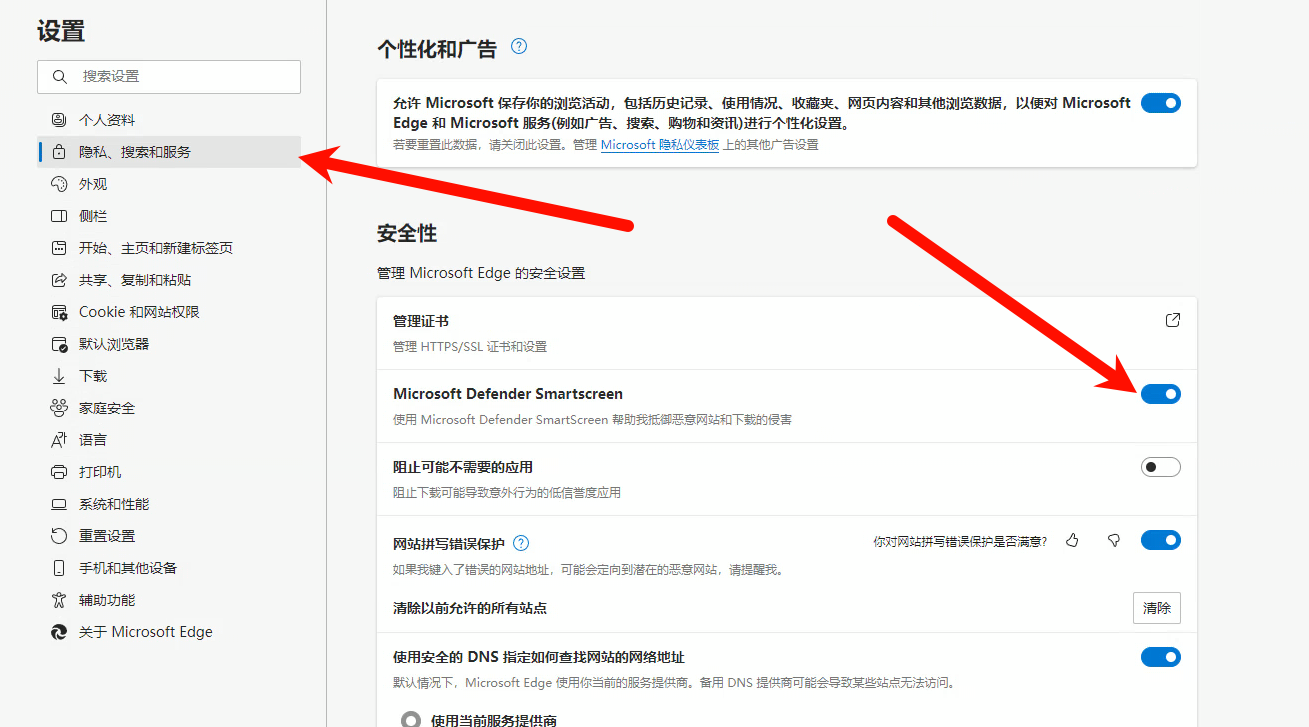
打开edge的设置-隐私、搜索和服务
关闭Microsoft Defender Smartscreen即可(它会在下载后扫描文件导致卡在100% 0KB/s)
解压
解压GPT-SoVITS一键包
如果你还有其他事要做(如准备数据集)则可以勾选低优先级模式
等待GPT-SoVITS解压完成即可
训练纳西妲声音模型
生成nahida.list
在GPT-SoVITS目录中新建一个raw_audio文件夹用于放置数据集
将先前下载的数据集解压进里面,并且建议将其放置在单独的文件夹中(即新建一个叫nahida的文件夹,再将*.wav和*.lab解压进去)
最终的目录结构看起来是这样的:
GPT-SoVITS\raw_audio\nahida\*.wav
GPT-SoVITS\raw_audio\nahida\*.lab
说明
.wav后缀为角色语音
.lab后缀为打标好的文件
之后打开GPT-SoVITS目录下的go-webui.bat打开web界面
进入webui后直接修改下图所指的位置
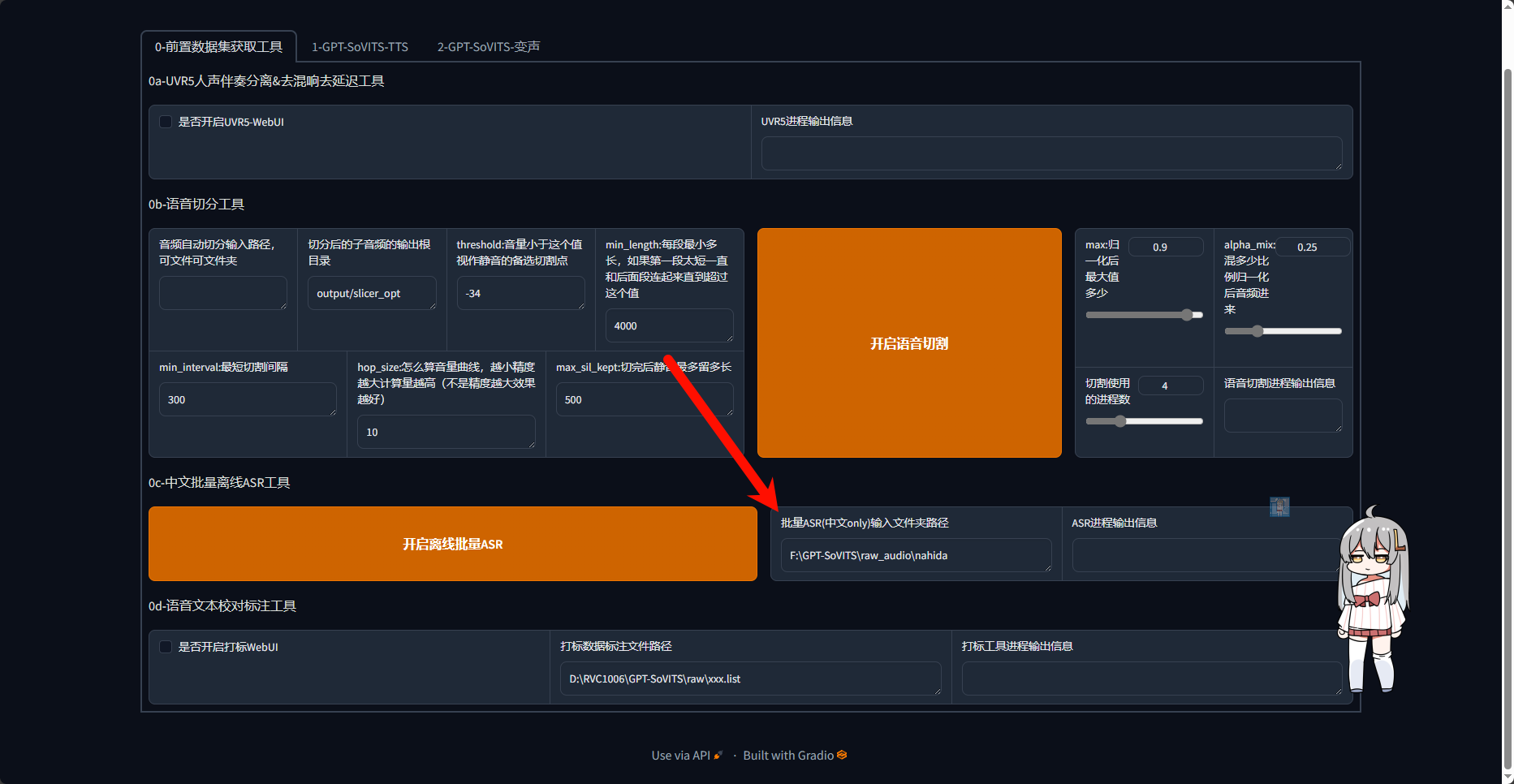
将其替换为你数据集(*.wav)所在的文件夹,如果你按照本教程操作,那么改为:
C:\Users\Administrator\Desktop\GPT-SoVITS-beta0128\raw_audio\nahida点击批量ASR后等待即可,当ASR进程输出信息中显示完成时进行下一步
若你还是不确定是否完成,可以前往output\asr_opt目录,打开nahida.list文件
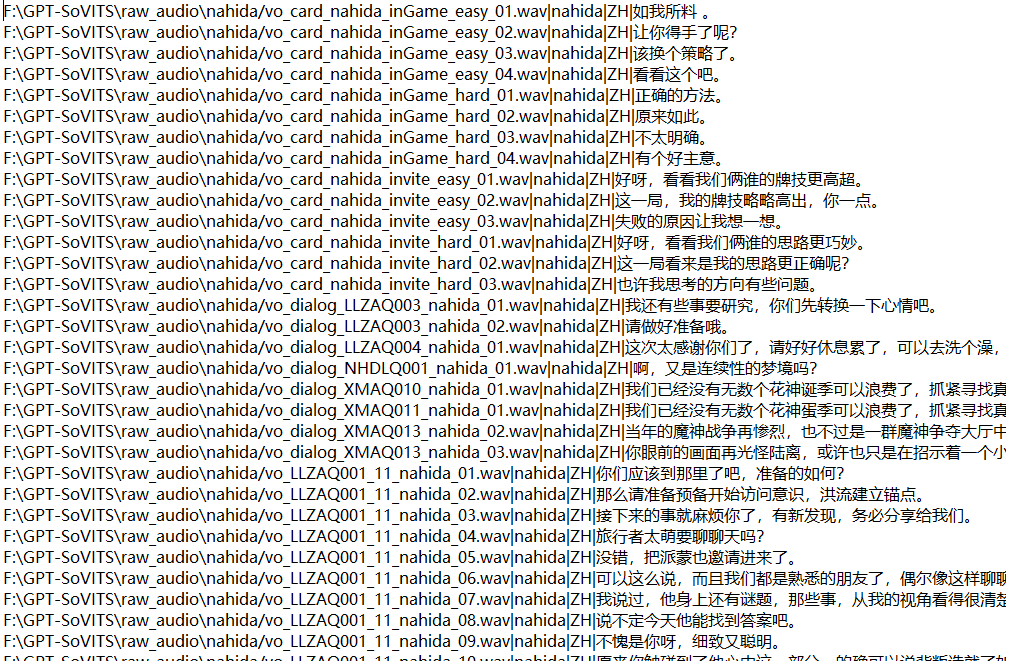
上图即为完成后的效果
准备训练
之后打开上方的第二个tab,修改红框中的内容

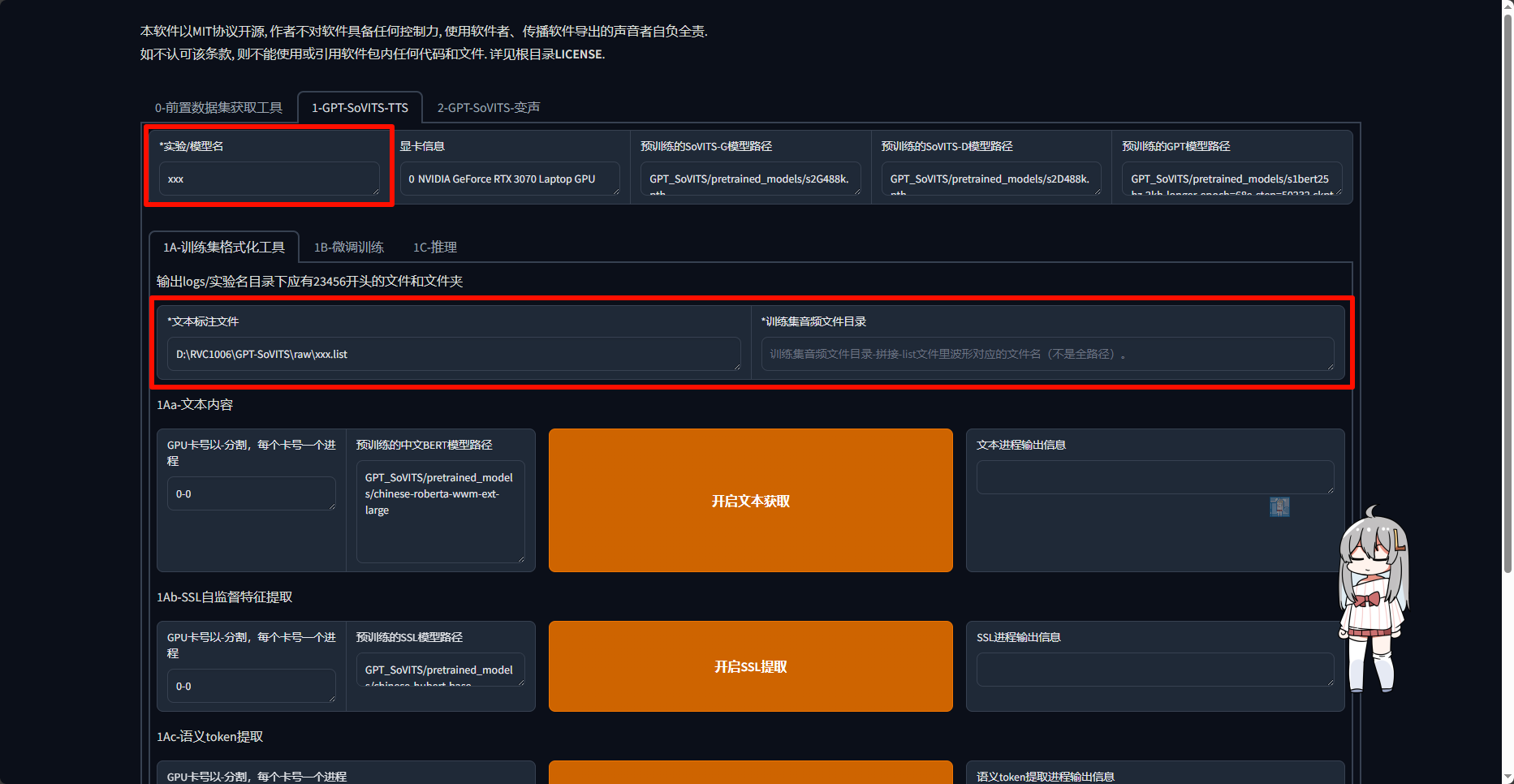
如果你按照本教程操作,下图三个框中的内容应该为
- nahida
- C:\Users\Administrator\Desktop\GPT-SoVITS-beta0128\output\asr_opt\nahida.list
- C:\Users\Administrator\Desktop\GPT-SoVITS-beta0128\raw_audio\nahida
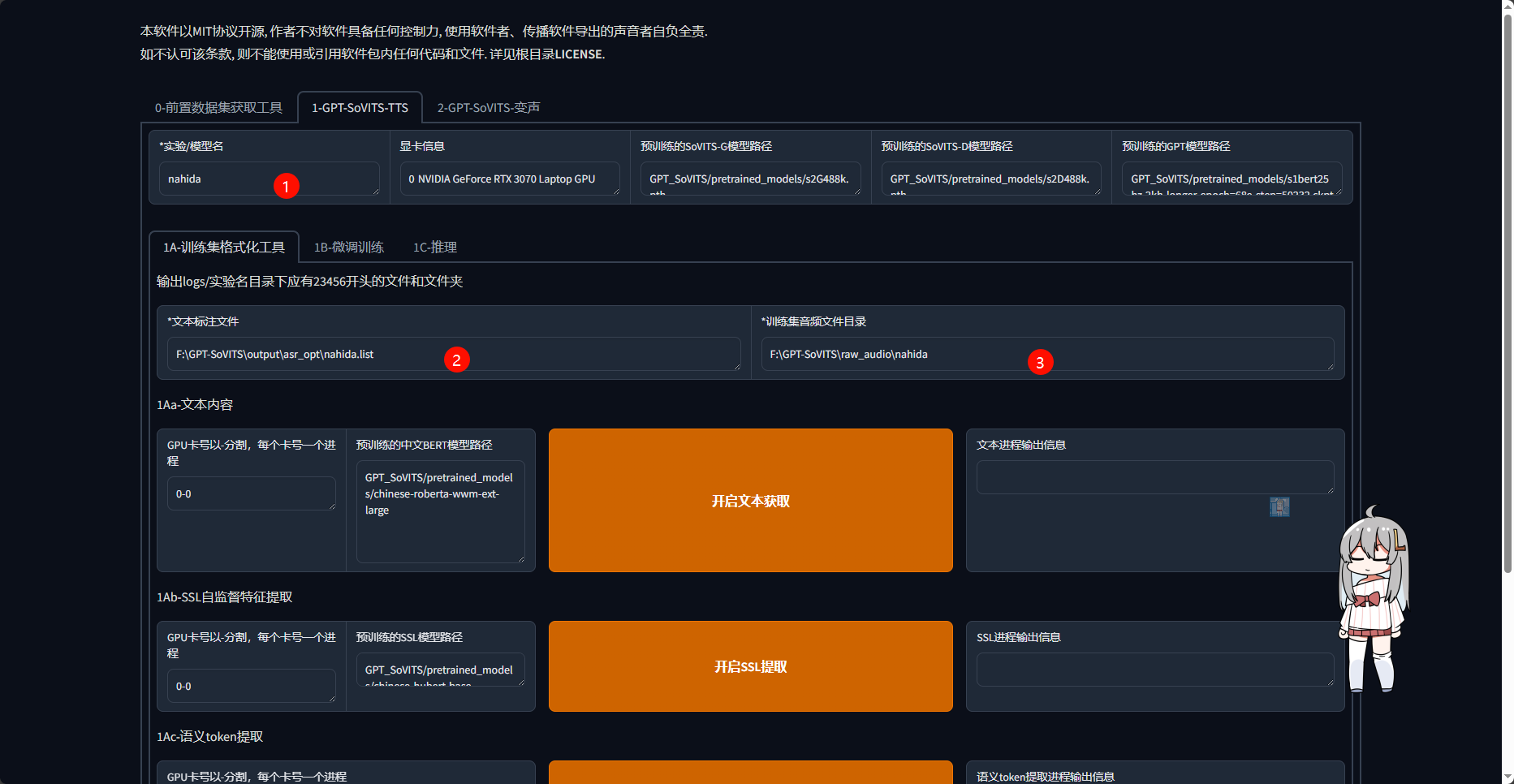
之后按顺序进行以下8步操作
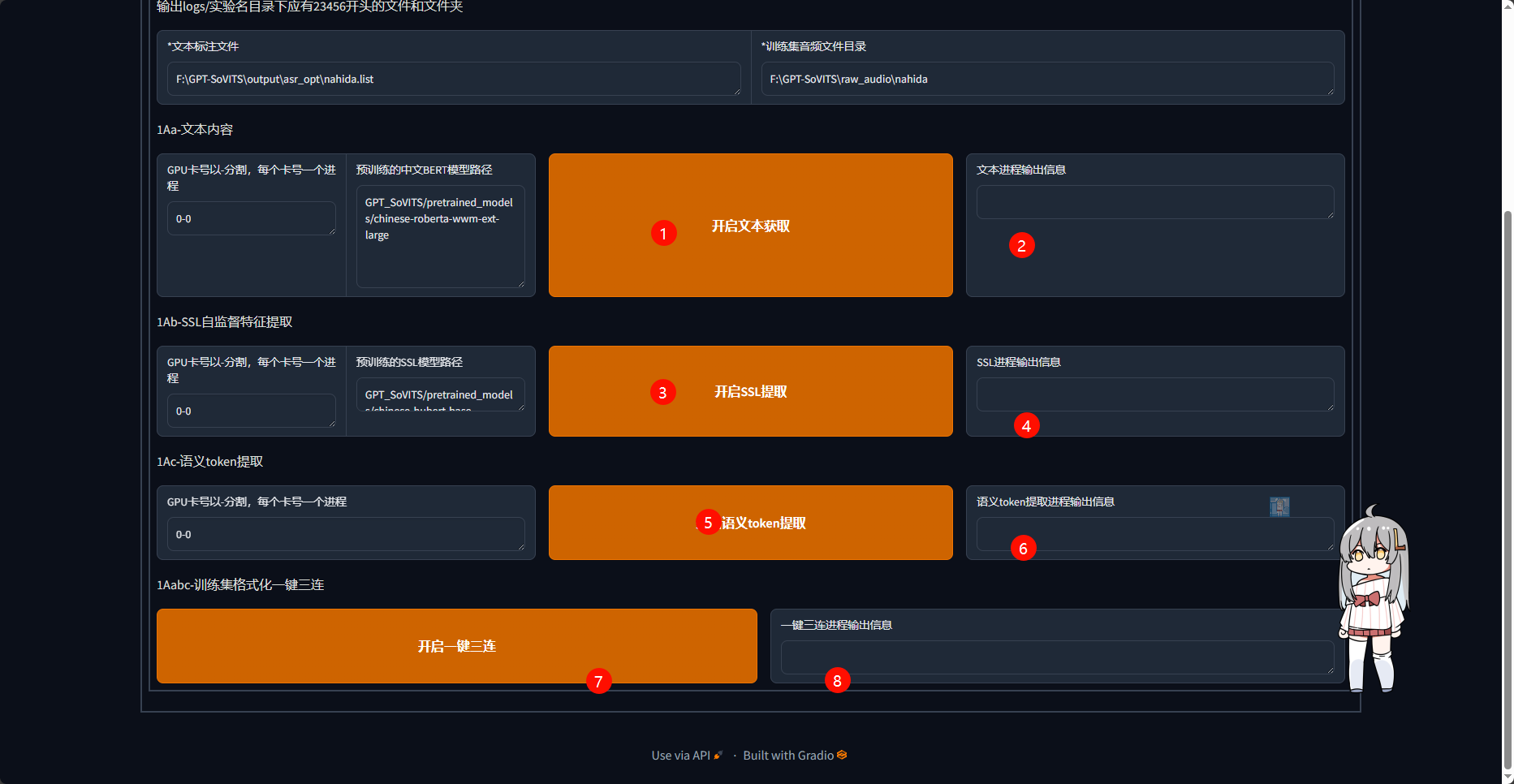
例:点击1的按钮后等待,直到2中提示任务完成,之后继续点击3观察4,如此往复
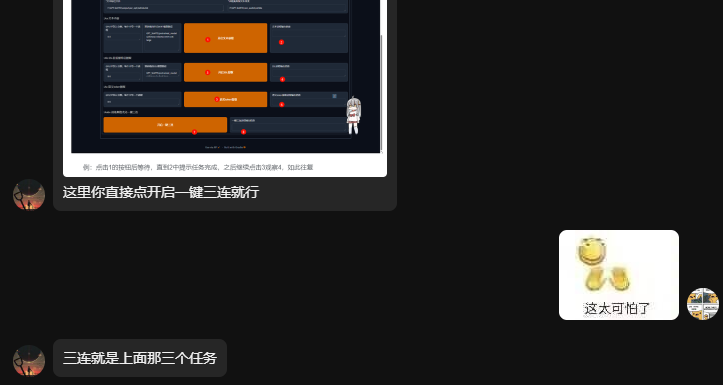
根据大佬指出,此处直接点击7(开启一键三连)即可
SoVITS与GPT训练
之后打开这个tab的第二个tab
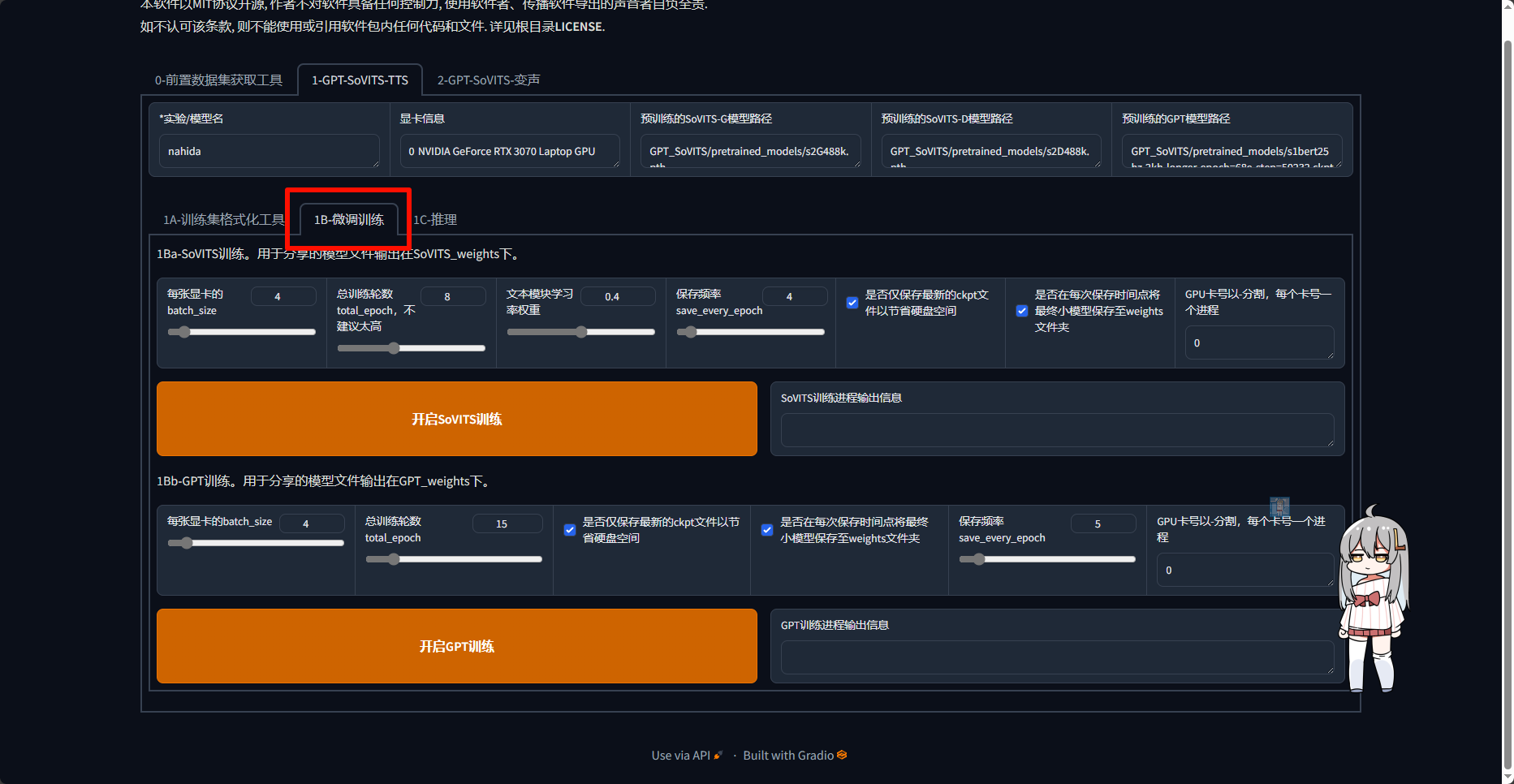
batch_size根据显存大小和模型数据量调整若使用8G显存的套餐,则所有保持默认即可
你需要分别进行SoVITS训练和GPT训练,都训练完成后才能进行推理
TTS音频推理
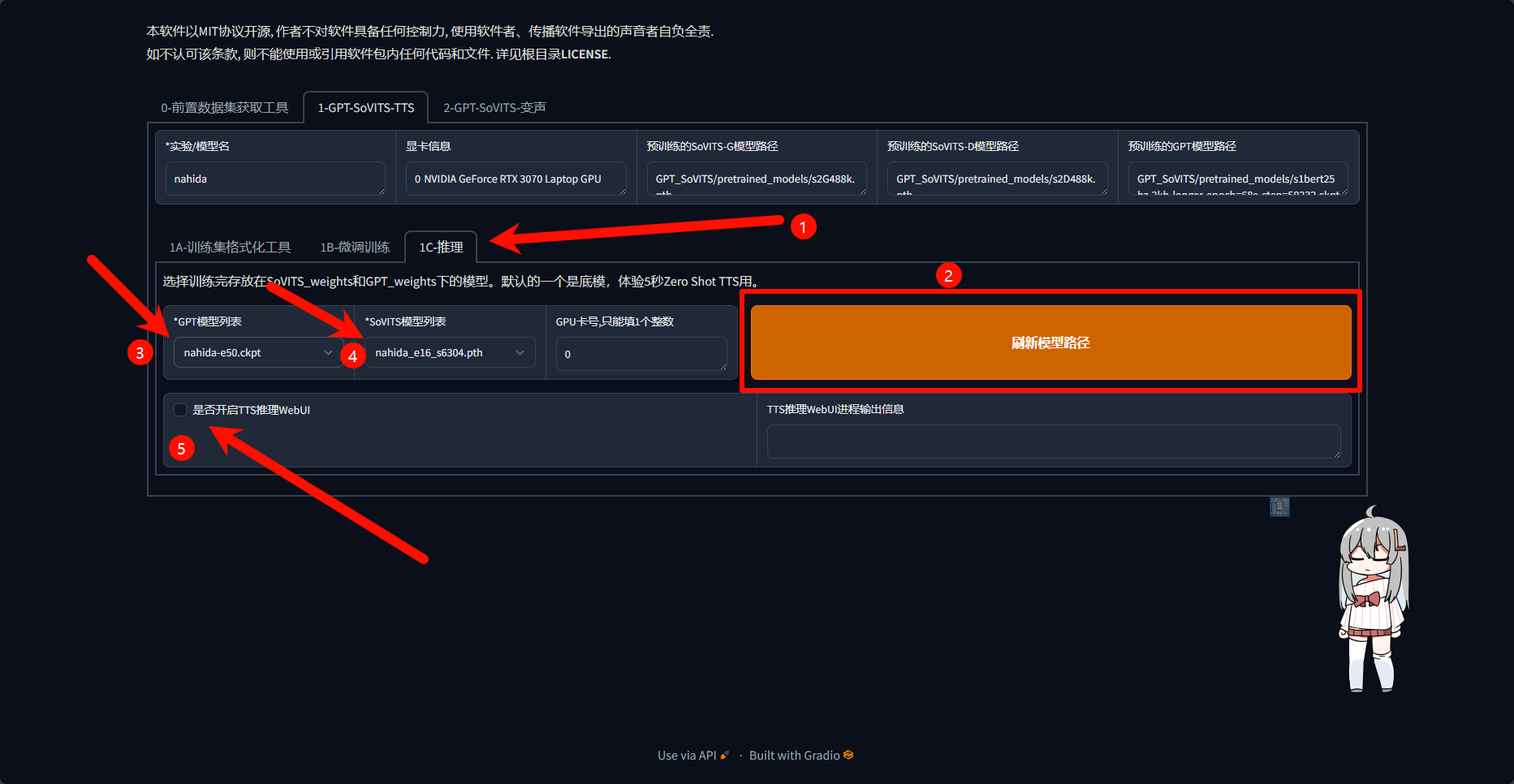
TTS推理WebUI进程输出信息中提示进程已开启后需要稍等1分钟左右加载模型
模型加载完成后会自动打开TTS推理webui,以下是主要功能区的介绍
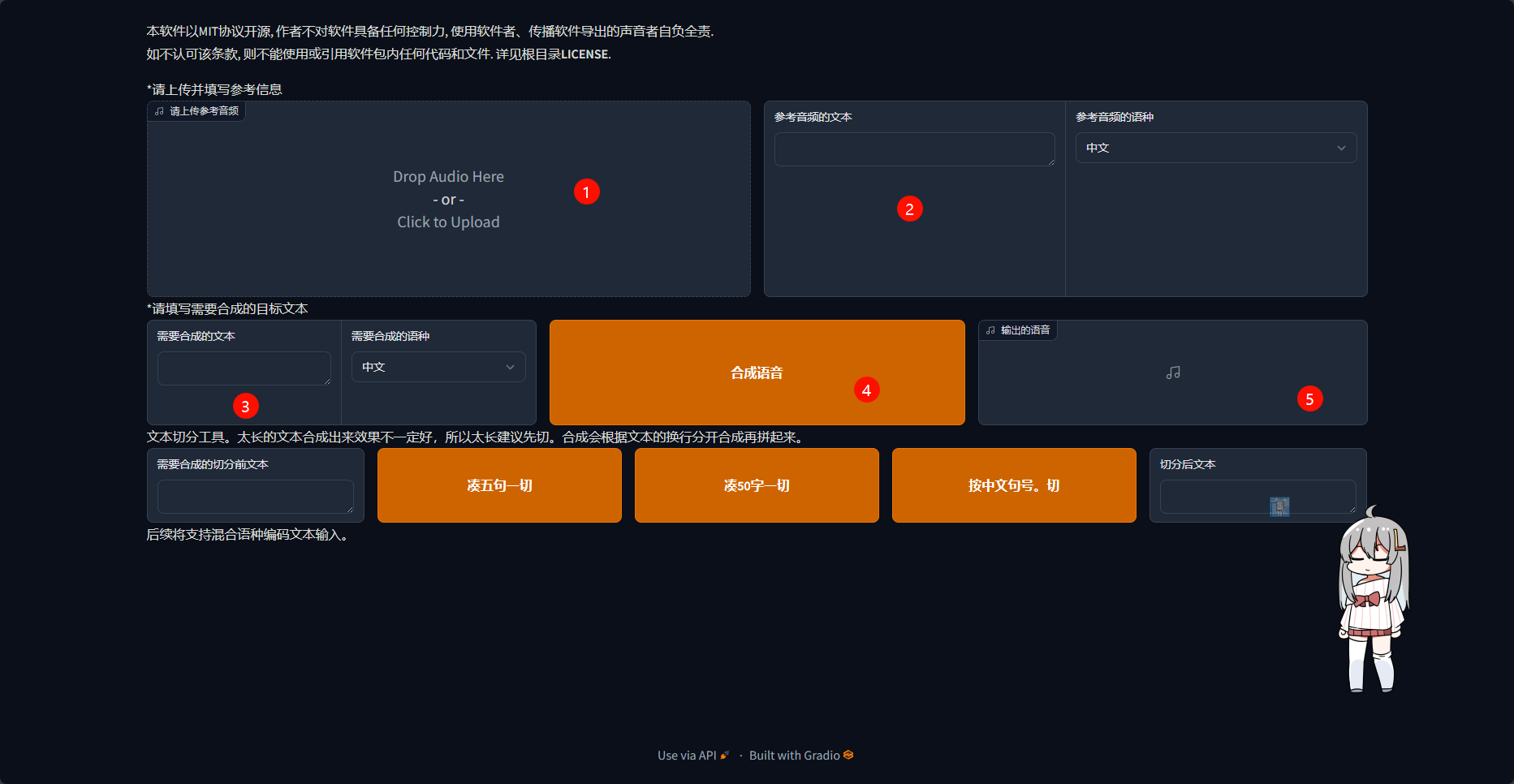
- 放置参考音频的地方(会影响最终推理出音频的语气与情绪)
- 参考音频中说了什么内容
- 你要把什么文本转换成语音
- 把3中的内容转换为语音
- 点击4后输出的音频
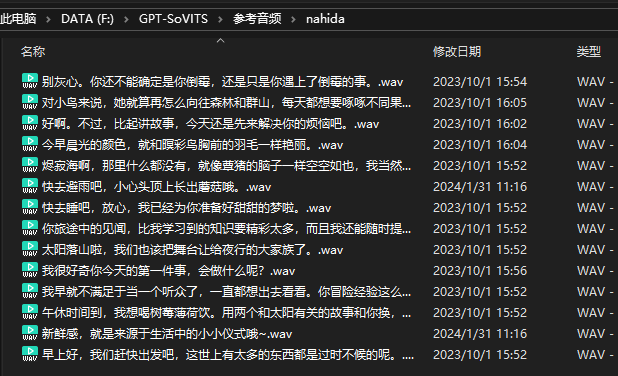
参考音频可以在数据集中随便找一些略长的音频
长文本合成效果: